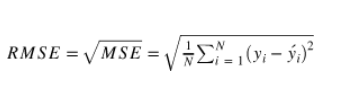[논문 리뷰] Masked Autoencoders Are Scalable Vision Learners(MAE)
Machine Learning/Deep Learning 논문 2021. 12. 27. 14:02반응형

Masked Autoencoders Are Scalable Vision Learners(MAE)
최근엔 주로 교신저자로만 이름을 올리던 Kaiming He 님의 1저자 논문인 MAE이다. 본 논문의 내용도 역시나 Kaiming He 답게 굉장히 유망한 결과를 보이고 있다. 항상 느끼는 것이, 이런 류의 논문은 성능 자체가 중요한 게 아니라, AI 연구의 한가지 방향성을 개척한다는 점에서 의미가 큰 것 같다.
Abstract
- 본 논문에서는 확장 가능한(Scalable) Self Supervised Learning 모델인 Masked AutoEncoder를 제안한다.
- MAE의 접근 방법은 간단하다. 입력 이미지의 Patch를 임의로 골라서 마스킹 작업하고, 손실된 픽셀을 재구축하는 방식으로 학습을 진행한다.
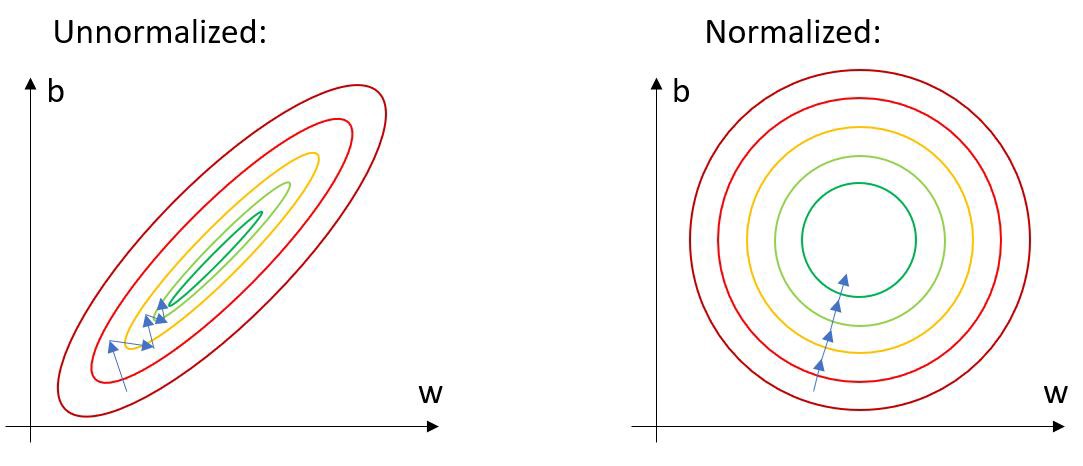
- 본 구조의 첫 번째 핵심 설계는, 비대칭 형태의 Encoder-Decoder 구조이다. Encoder는 Masking된 patch를 제외하고 Visible Patches만을 사용한다. 반면 Lightweighted Decoder는 여기서 얻어진 Encoder에서 얻어진 Latent Representation과 Masked Patches를 함께 사용하여 이미지를 Reconstruction 한다.
- 두 번째 핵심 설계는, 높은 masking 비율이다. 본 논문에서는 효과적인 Self Supervisory Task를 수행하기 위해서 75%의 Mask Ratio를 가지고 있다. 너무 작은 Masking 비율을 둘 경우, Image의 각 픽셀은 그다지 Semantic하지 않기 때문에 단순히 주변 영역을 보고 쉽게 추론할 수 있기 때문에 높은 Masking을 통해 학습을 진행하였다.
- 이러한 두가지 설계를 합쳐서 구현한 MAE는 3배 이상의 속도 향상을 이뤄냈고, (인코더의 입력 차원이 줄었으므로), 정확도 또한 ImageNet 1K 데이터만으로 ViT-Huge에서 87.8%의 정확도를 얻어냈으며, 이는 기존 Supervised Learning 방식의 정확도보다 높다.
- 뿐만 아니라, Downstream Task에서도 기존 지도 학습 방식을 능가하는 정확도를 보였으며, Vision Task도 BERT와 같은 Masking 방식으로 Self Supervised Learning을 통해 이해능력을 학습시킨 후, 그를 바탕으로 Fine Tuning Approach가 가능하다는 방향성을 제시한 유망한 결과를 보인다.
Introduction
- 딥러닝 연구가 빠르게 성장함에 따라 좀 더 크고, 거대한 딥러닝 아키텍쳐들이 쏟아져 나오고 있다.
- 하드웨어가 발전하면서, 이러한 거대한 아키텍처의 모델들은 백만장정도의 이미지에는 너무나도 쉽게 Overfitting되고 있으며, 이제는 수백만장의 이미지를 통해 학습을 하려는 시도가 늘고 있다.
- 많은 데이터에 대한 이러한 수요는 NLP 분야에서 Self-supervised pre-training이라는 방법론을 통해 효과적으로 해결되었다. GPT와 BERT와 같은 모델은 데이터의 일부를 제거하고, 원본 데이터를 예측하는 방식으로 학습을 진행한다.
- 본 논문에서 제안하는 MAE의 기존 개념은 좀 더 General한 Denoising AutoEncoder라고 볼 수 있으며, 이는 Vision Task에서 자연스럽게 적용이 될 수 있다. 실제로 비슷한 다른 연구 사례가 BERT 이전에 존재하기도 했었다.
- 그럼에도 불구하고, BERT에서 대단히 성공적이었던 이러한 방법론은 Vision 분야에서는 그다지 큰 효용을 얻지 못했다는점에서 한가지 의문이 발생한다. Masked Autoencoding이 왜 Vision과 NLP 분야에서 차이를 가지는가?
- 저자들은 첫째로, Vision과 NLP의 근본적인 구조 차이를 원인으로 꼽았다.
기존 Vision Task에서는 CNN이 압도적으로 우세했고, CNN은 정규 이미지를 입력으로 받아 처리를 진행하는 과정을 거치므로, Mask Token이나 Positional Embedding과 같은 부수적인 Indicator들을 적절히 통합하는 것이 굉장히 어려운 일이었다. 하지만, 최근 ViT가 소개됨에 따라 이러한 구조의 차이는 더 이상 장애물이 되지 않는다. - 둘째로, 정보의 밀도 자체가 다르다는 점을 꼽았다. 언어는 사람이 직접 만드는 일종의 고밀도 신호체계라고 볼 수 있다. 단순히 몇개의 Missing Word를 찾아내는 과정에서도 매우 높은 수준의 언어적 이해가 필요하기 때문이다.
- 반면, 이미지의 경우, 공간적 특성을 매우 크게 담고 있는 일종의 자연 신호이다. 따라서, 특정 patch가 지워진다고 하더라도 주변의 patch를 통해 손쉽게 복원이 가능하며, 그다지 높은 수준의 이미지 이해 능력이 없더라도 쉽게 수행될 수 있다.
- 본 논문에서는 이러한 단점을 타파하기 위해 굉장히 높은 비율로 Masking을 진행한다. 이러한 전략을 통해 이미지 전반을 충분히 이해하지 못하면 복원이 불가능하게끔 유도하여 효과적인 학습을 유도할 수 있다.
- 뿐만 아니라 비대칭성 Encoder-Decoder 구조를 통해서 Encoder에서는 전체 패치의 25%(Visible Patches)만을 사용하고, 이를 통해 메모리 사용량과 학습 속도를 개선시켜 거대한 모델에도 효과적으로 적용할 수 있다.
- 해당 방법을 ViT-Large/Huge에 적용한 결과 ImageNet-1K에서 더 높은 일반화 성능을 보여주었으며 87.8%의 정확도를 달성하여 기존 방식보다 우수함을 입증하였다.
Approach
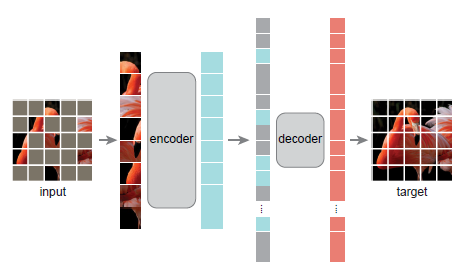

- Masking의 경우 75%정도로, 매우 높은 비율의 Masking을 진행함으로써 주변 Pixel을 통해 단순히 Masked Patches를 찾아낼 수 없도록 유도한다.
- MAE Encoder 부분은 ViT를 그대로 사용하였으며, 차이점은 Visible(Unmasked Patches)만을 사용했다는 점이다. 이러한 특성으로 인해 메모리 사용량 및 계산량에서 큰 이점을 가지며, 전체 입력 데이터의 25%만을 사용하는 효과가 있다.
- MAE Decoder는 Visible과 Masked Patches를 모두 사용하는 방식으로 구성되며, 비어있는 patches들을 채워 넣는 방식으로 reconstruction을 진행한다. decoder는 사전 학습시에만 사용되기 때문에 Encoder와 별개로 사용자들이 원하는 디자인으로 유동적으로 변경할 수 있는 구조이다. Decoder 자체는 Encoder에서 Latent Vector만 잘 뽑아낸다면 상대적으로 그다지 복잡한 작업을 요하지 않기 때문에 저자들은 Encoder보다 좁고 짧은 lightweight decoder 구조를 사용하였으며 성능 차이가 그렇게 크지 않았다고 한다.
- 학습할때는 Masked Patch에 대해서만 MSE(Mean Squared Error)를 구하는 방식으로 진행되며, 이는 BERT의 학습 메커니즘과 동일하다.
Experiments
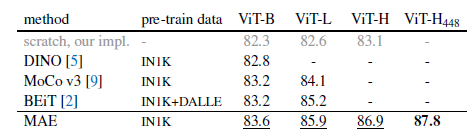
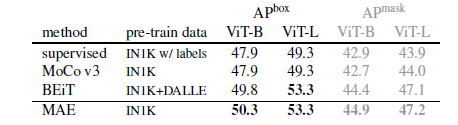
- 기존 방식들에 비해서 더 높은 Generalization 성능을 바탕으로 정확도가 향상되었다.
- 뿐만아니라, Random Sampling과 Masking 자체가 이미 꽤나 강력한 Augmentation과 같은 기능을 하기 때문에, 최소한의 Augmentation만으로도 높은 정확도를 달성할 수 있었다고 한다.
- 기존 방식 대비 Encoder에서 사용하는 입력 사이즈가 1/4 정도 수준이기 때문에, Parameter가 보다 적고 가벼우며, Scalable 한 특성을 지닌다.
Conclusion
- 본 논문은 NLP에서 자주 쓰이는 방식인 Self-Supervised Learning을 Vision Task에도 적용시키기 위한 MAE를 제안하였다.
- 매우 높은 Masking Ratio를 통해 단순히 주변 Pixel을 활용하여 추론이 불가능하도록 하게 함으로써, 모델로 하여금 Visual Understanding을 학습하도록 강제하고, 실제로 유망한 결과를 얻어낼 수 있었다.
- 뿐만 아니라, 위와 같은 방식으로 전체적으로 Image를 보는 방법에 대해 학습한 모델은, Down-stream Task에 대해서도 약간의 Fine-tuning을 진행하면 마치 BERT와 같이 효과적으로 동작함을 보였다.
- Encoder에서 25%정도의 Patch를 사용하는 방식을 통해 ViT의 한계점이라고도 볼 수 있는 고화질, 대량 데이터 학습에 있어서 보다 빠른 학습이 가능하고 Down-stream Task에 빠르게 적용시킬 수 있는 Scalable 모델을 제시하였다는 점이 가장 큰 Contribution이라고 생각한다.
- 역시 Kaiming He답게 굉장한 내용의 논문이었다. 구현 난이도와 Concept 자체는 심플하지만, 강력한 성능을 가지는 방법. 항상 존경스러운 마음뿐이다.
반응형
'Machine Learning > Deep Learning 논문' 카테고리의 다른 글

Hyunsoo Luke HA
석사를 마치고 현재는 Upstage에서 전문연구요원으로 활동중인 AI 개발자의 삽질 일지입니다! 이해한 내용을 정리하는 용도로 만들었으니, 틀린 내용이 있으면 자유롭게 의견 남겨주세요!