


[논문 리뷰] Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation(GRU)
Machine Learning/Deep Learning 논문 2021. 12. 20. 03:36
Learning Phrase Representations using RNN Encoder Decoder for Statistical Machine Translation
자랑스러운 한국인 연구자이신 조경현 교수님의 논문으로, Seq2Seq의 근원이 된 논문이다. 본 논문은 RNN에서의 Encoder Decoder를 최초로 제시했을 뿐만 아니라, LSTM을 보다 효율적으로 바꾼 GRU(Gated Recurrent Unit)을 제안했다. Encoder Decoder 구조는 나중에 Seq2Seq 논문 리뷰에서 자세히 다루고(본 논문의 저자인 조경현 교수님께서 Seq2Seq에 최초로 Attention을 도입한 논문도 있다!) 본 포스팅에서는 LSTM에 이어서 GRU만 일단 다뤄보도록 하자.
LSTM 개념을 숙지하지 않으셨다면, LSTM 논문 리뷰를 먼저 보고 오시면 이해가 보다 쉬울 것이다.
2021.12.20 - [Machine Learning/Deep Learning 논문] - [논문 리뷰] LONG SHORT-TERM MEMORY
[논문 리뷰] LONG SHORT-TERM MEMORY
LONG SHORT-TERM MEMORY(LSTM) RNN의 전설을 쓴 논문 LSTM이다. 1997년에 어떻게 이런 구조를 고안해내셨는지 놀라운 따름이다.비록 1997년에 연구되었지만, 아직까지도 시계열 분석등에 종종 사용되고 있는
cryptosalamander.tistory.com
GRU(Gated Recurrent Unit)

- LSTM은 기존 Vanilla RNN의 한계점인 Long-Term Dependency에 강인하도록 Cell State 개념과 Forget Gate, Input Gate, Output Gate의 3가지 Gate를 적용하여 장기간에도 정보를 손실하지 않도록 하였다.
- GRU는 LSTM의 구조에서 영감을 받아 만들어졌으며, 기존 Gate의 중복성을 제거하고 보다 효율적인 방식으로 처리하기 위해서 보다 간단한 구조를 제안한다.
- Cell State 개념을 없애버리고, 다시 hidden state 단일 방식으로 사용하되, Long Term Dependency 문제는 여전히 효과적으로 해결할 수 있는 방식을 제안한다.
- 기존 LSTM의 Forget Gate와 같은 역할을 수행하는 Reset Gate와 Input Gate와 Forget Gate의 개념을 합친 Update Gate로 이루어져있다.
Reset Gate


- 과거의 hidden state 값을 적절히 버려주는 역할을 하는 Gate로 직전 시점의 hidden state와 현시점의 입력값에 W를 곱해서 얻어지며, LSTM과 같이 Sigmoid함수를 통해 0~1 사이의 값을 지니게끔 한다.
Update Gate


- LSTM의 Forget Gate와 Input Gate의 혼합 방식이다.
- 이전 hidden state와 현재 입력값의 state를 어떤 비율로 입력할 것인지를 정하는 방식으로 두개의 Gate를 합쳤다.
- 예를 들어, u(t)가 1일 경우, forget gate가 열리고 input gate가 닫히며, 반대로 u(t)가 0일 경우, input gate가 열리고 forget gate가 닫힌다.
- GRU는 별도의 output gate가 없어서 다음과 같은 순서로 최종 hidden state를 정한다.

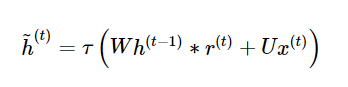
- 현재 unit의 입력값 x(t)와 h(t-1)을 바탕으로 임시 h(t)를 계산한다.
- 그 후, 임시h(t)와 update gate의 결과값을 적절히 합쳐서 최종 hidden state h(t)를 계산한다. 그림으로 확인하면 다음 프로세스에 해당한다.


GRU Conclusion
- LSTM과 구조적으로 매우 유사하며, 성능은 LSTM과 거의 비슷한 수준이다.
- 특정 Task에선 LSTM이 더 좋을 때도 있고, 반대로 GRU가 더 좋을 때도 있다.
- 다만, GRU는 학습을 통해 parameter를 얻어야 하던 Gate의 수가 1개 줄었기 때문에 학습해야 할 weight가 적다는 것이 장점이라고 볼 수 있겠다.
'Machine Learning > Deep Learning 논문' 카테고리의 다른 글

Hyunsoo Luke HA
석사를 마치고 현재는 Upstage에서 전문연구요원으로 활동중인 AI 개발자의 삽질 일지입니다! 이해한 내용을 정리하는 용도로 만들었으니, 틀린 내용이 있으면 자유롭게 의견 남겨주세요!