[에러노트 / TPU] terminate called after throwing an instance of 'std::bad_alloc', Core Dumped(Aborted)
Machine Learning/GCP & TPU 고군분투 2021. 10. 6. 03:45반응형

TPU terminate called after throwing an instance of 'std::bad_alloc', Core Dumped(Aborted) 해결법
에러 메시지
ttcmalloc: large alloc 500236124160 bytes == (nil) @ 0x7f51b5df3680 0x7f51b5e13ff4 0x7f51b590a309 0x7f51b590bfb9 0x7f51b590c056 0x7f4e5cc6a659 0x7f4e526a0954 0x7f51b5fe7b8a 0x7f51b5fe7c91 0x7f51b5d46915 0x7f51b5fec0bf 0x7f51b5d468b8 0x7f51b5feb5fa 0x7f51b5bbb34c 0x7f51b5d468b8 0x7f51b5d46983 0x7f51b5bbbb59 0x7f51b5bbb3da 0x67299f 0x682dcb 0x684321 0x5c3cb0 0x5f257d 0x56fcb6 0x56822a 0x5f6033 0x56ef97 0x5f5e56 0x56a136 0x5f5e56 0x569f5e
terminate called after throwing an instance of 'std::bad_alloc'
what(): std::bad_alloc
https://symbolize.stripped_domain/r/?trace=7f51b5c2918b,7f51b5c2920f&map=
*** SIGABRT received by PID 14088 (TID 14088) on cpu 95 from PID 14088; stack trace: ***
PC: @ 0x7f51b5c2918b (unknown) raise
@ 0x7f4f86e6d800 976 (unknown)
@ 0x7f51b5c29210 (unknown) (unknown)
https://symbolize.stripped_domain/r/?trace=7f51b5c2918b,7f4f86e6d7ff,7f51b5c2920f&map=2a762cd764e70bc90ae4c7f9747c08d7:7f4f79f2b000-7f4f871ac280
E0628 16:55:18.669807 14088 coredump_hook.cc:292] RAW: Remote crash data gathering hook invoked.
E0628 16:55:18.669833 14088 coredump_hook.cc:384] RAW: Skipping coredump since rlimit was 0 at process start.
E0628 16:55:18.669843 14088 client.cc:222] RAW: Coroner client retries enabled (b/136286901), will retry for up to 30 sec.
E0628 16:55:18.669852 14088 coredump_hook.cc:447] RAW: Sending fingerprint to remote end.
E0628 16:55:18.669864 14088 coredump_socket.cc:124] RAW: Stat failed errno=2 on socket /var/google/services/logmanagerd/remote_coredump.socket
E0628 16:55:18.669874 14088 coredump_hook.cc:451] RAW: Cannot send fingerprint to Coroner: [NOT_FOUND] Missing crash reporting socket. Is the listener running?
E0628 16:55:18.669881 14088 coredump_hook.cc:525] RAW: Discarding core.
E0628 16:55:18.673655 14088 process_state.cc:771] RAW: Raising signal 6 with default behavior
Aborted (core dumped)정말 사람을 미치게 하는 에러였다.
아무리 검색해도, TPU 학습에 대한 정보는 매우 미미하고, 해결법 또한 정말 상상도 못한 방법이었기에,
최대한 많은 분들이 TPU 학습에 있어서 나와 같은 삽질을 하지 않기를 바라는 맘으로 글을 작성한다.
에러 발생 지점
# Transformer 기반 NLP 모델과 함께 사용시
xmp.spawn(map_fn, args=(flags,), nprocs=8, start_method='fork')
해결법
해결 방법을 아무리 검색해도 잘 나오지 않아서 포기에 가까운 상태였다가,
Transformer와 함께 사용할 때 해당 증상이 발생하는 점을 고려하여,
Transformer Github Issue를 뒤져본 결과,
나와 같은 현상을 호소하는 사람이 있었고, 놀라운 답변을 발견했다.
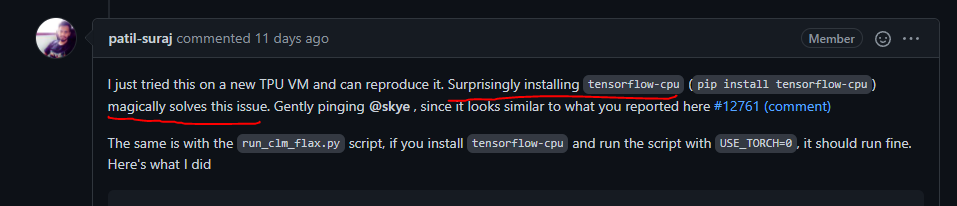
왜인지는 모르겠지만, tensorflow-cpu를 설치하면 에러가 놀랍게도 사라진다고 한다.
나는 코드가 완전히 pytorch 베이스였기 때문에 당연히 해당 사항으로 해결이 안될거라고 생각했지만,
이거 된다!
TPU-VM 자체가 내부적으로 Tensorflow를 사용해서 그런지, tensorflow-cpu를 설치하는 순간 에러가 사라졌다!
설령 Tensorflow를 사용하지 않는다고 하더라도 Core dump가 뜨면 무조건 pip install tensorflow-cpu를 시도해보자.
반응형
'Machine Learning > GCP & TPU 고군분투' 카테고리의 다른 글
| [GCP / Google Cloud Platform] GCP Disk 용량 추가하기 (0) | 2021.08.02 |
|---|

Hyunsoo Luke HA
석사를 마치고 현재는 Upstage에서 전문연구요원으로 활동중인 AI 개발자의 삽질 일지입니다! 이해한 내용을 정리하는 용도로 만들었으니, 틀린 내용이 있으면 자유롭게 의견 남겨주세요!