ResNeXt: Aggregated Residual Transformations for Deep Neural Networks
Kaiming He의 또 다른 논문, ResNeXt를 리뷰해보자.
연구의 배경
시각 데이터를 다루는 연구들은 이제 단순히 Feature를 잘 처리하는 Feature Engineering 뿐만 아니라, 효율적으로 학습이 가능하도록 Network 설계를 잘 만드는 Network Engineering으로 전환됨
하지만 Architecture를 설계하는 것은 매우 어려운 일인데, 그러한 원인 중 한 가지는 하이퍼 파라미터의 수가 점점 늘어남에 따라 연구자들이 여러가지 Task에 대해서 적절한 하이퍼 파라미터를 설정하는게 어렵기 때문이다.
ResNeXt는 ResNet을 계승받아 항상 일정한 형태를 가지는 Convolution층 여러개를 쌓아서 만들어지며(Residual Block), 이로 인해 레이어별로 Kernel Size를 어떻게 할지와 같은 고민으로부터 연구자들을 해방시킬 수 있다.
또한 Inception 모델들이 가지는 주요 특성인 Split-Transform-Merge의 특성을 적용하여 높은 정확도를 얻었다.
Split - Transform - Merge
ResNeXt의 핵심은 ResNet 구조의 Architecture에 Inception에서 사용하던 Cardinality 개념을 도입하여 Convolution 연산을 쪼개서 진행하고, 서로 다른 Weight를 구한뒤 합쳐주는 Split-Transform-Merge를 추가한 것이다.
이 때, 쪼개진 CNN이 몇개의 path를 가지는지를 결정하는 하이퍼파라미터가 바로 Cardinality이며, 각각의 path에서 가지는 채널을 depth라고 정의한다.
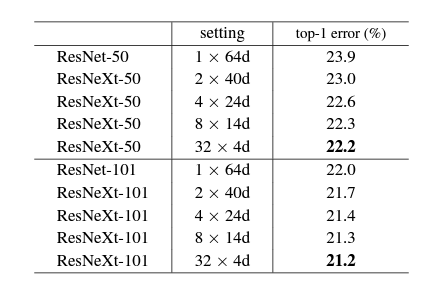
따라서 위 그림은, Conv2 Stage 기준 32개의 path와 4의 사이즈를 가지므로, Cardinality = 32, detph = 4의 ResNeXt-50 (32x4d)로 정의할 수 있다.
ResNet과의 구조 차이는 위 그림과 같다.
실험 결과
ResNeXt가 Inception의 Split - Transform - Merge 개념을 도입한 것 만으로도 ResNet을 상회하는 성능을 가지게 되었다.
저자는 실험을 통해, 모델의 깊이를 늘리거나, 채널을 늘리는 것보다 단순히 Cardinality를 올림으로써 가장 적은 계산량증가로 최대의 성능 향상 효용을 얻을 수 있다고 설명했다.
실제로 Cardinality를 64로 설정한 ResNeXt-101이, ResNet200과 ResNet-101에서 채널을 100으로 늘린 네트워크보다 더 좋은 성능을 보이는 것을 확인할 수 있다.
딥러닝 모델은 기본적으로, 랜덤으로 생성된 Weight 값으로 시작해서 점차 Loss를 줄여나가는 방식으로 학습을 진행하게 된다. 이 때, 처음 Weight를 초기화 하는 방법에 대한 다양한 연구가 진행되어있는데, 그 이유는 Weight Initialization방식에 따라 실제 성능에서도 유의미한 차이를 가지기 때문이다.
위 그림을 보자, 시작하는 Initial 값이 달랐던 것 뿐인데, 최종적으로 계산된 Cost Function의 값이 차이가 난다는 것을 확인할 수 있다. 그리고 만약 initialization이 오른쪽 봉우리의 최상단에서 시작되거나 할 경우엔, 두개의 봉우리 사이의 Local Optima에 갇히게 될 수도 있다.
이처럼 Weight를 초기화하는 방법은 꽤 유의미한 차이를 지니며, 다양한 방법이 연구되어있다.
Simple Initialization
먼저 가장 단순하게 생각해 볼 수 있는 방법은, 모든 weight를 0이나 1과 같은 숫자로 시작하는 것이다.
하지만 이는, 학습 과정에서 Back Propagation의 값을 동일하게 만들고, 어떤 Feature가 중요한지 효과적으로 학습을 하지 못하게 되는 결과를 낳는다.
따라서 초기화는 반드시 서로 다른 다양한 값으로 넣어주어야 한다.
Random Initialization
말 그대로 임의의 수를 넣는 방식이다. 실제로 대부분의 효과적인 Initialization은 다 일종의 Random Initialization이라고 볼 수 있다. 다만 임의 값의 분포를 어떻게 처리할지, 각각의 값에 대한 가중치는 어떻게 처리할지에 따라 다양한 방법이 존재한다.
Xavier Initialization
임의로 값을 생성하되, 임의 값의 표준 편차를 직전 Hidden Layer의 개수 n, 현재 Hidden Layer의 개수 m을 기준으로 하여 2 / root(n+m) 을 표준편차로 하는 정규분포를 따르게끔 초기화한다.
이는 데이터의 Activation Function 값을 더욱 고르게 퍼지게 할 수 있고, 레이어가 깊고 클 수록 그에 맞게 표준편차가 조정되는 적응형 방식이기 때문에 보다 Robust한 결과값을 얻을 수 있다.
해당 이름은, 연구의 발표자 Xavier Glorot의 이름을 따서 만들어진 초기화 방법으로, Glorot Initialization이라고도 한다.
일반적으로, Activation이 Sigmoid일 때 Xavier를 사용하며, pytorch에서는 아래 명령어를 통해 사용한다.
He Initialization은 ResNet으로 유명한 Kaiming He의 이름을 따서 만들어졌으며, 마찬가지로 Kaiming Intialization이라고도 한다. Xavier와 달리 ReLU Activation Function과 함께 사용되는데, 표준편차를 root(2 / n)으로 초기화한다.
Xavier Initialization의 경우, ReLU와 함께 사용하면 다음과 같이 값이 점점 분포가 치우치고, 깊은 Layer 구조에서 Gradient Vanishing을 발생시킬 수 있다.
출처 : https://yngie-c.github.io
하지만, He Initialization의 경우, 아래와 같이 분포를 유지하면서 Gradient Vanishing을 막을 수 있다는 장점이 있다.
ResNet : deep residual learning for image recognition
세계적인 딥러닝 연구자인 Kaiming He 님이 작성하였고, Computer Vision 역사의 한 획을 그은 논문인 ResNet을 간략히 알아보자.
연구의 배경
컴퓨터 비전 분야에 있어서, 깊은 네트워크는 이미지의 다양한 Feature를 학습할 수 있다는 점에서, 매우 중요한 일이라고 평가받는다.
하지만, 2015년 당시, VGG16과 VGG34를 CIFAR 10 데이터셋에서 학습시켰을 때, 오히려 VGG 34가 더 깊은 구조를 가지고 있음에도 불구하고 정확도가 떨어지는 현상이 관측되었다.
원래 네트워크가 깊어질 수록, Gradient Vanishing, 오버피팅등 다양한 Degradation이 발생하지만, 저자가 직접 parameter들을 추적하며 실험한 결과, 이는 단순히 Gradient Vanishing과 오버피팅으로 인한 문제가 아닌, Convergence Rate가 낮아서 발생하는 문제로 정의했다. 즉 Global Optima로 수렴하는 속도(학습 진도)가 너무 느리다는 것이다.
본 논문에서는, Layer가 깊어져도 학습이 잘 진행될 수 있도록 하는 Residual Block 개념을 제시한다.
Residual Block
H(X)를 한번에 구하는것이 너무 어려우니, F(x) = H(x) - x를 만족하는 F(x)를 학습한다.
입력값 x를 identitiy mapping으로 사용하므로, 추가적인 파라미터나 계산 복잡도 증가가 발생하지 않는다.
만약 x가 optimal한 identity mapping이라면, F(x)의 값이 0에 가깝게 수렴하게 되어, VGG-16과 VGG-34에서 나타난 현상처럼, 적어도 깊은 레이어가 얕은 레이어 구조보다 Error가 더 큰 상황은 방지할 수 있을 것이라는 가정에서 고안되었다.
각각의 블록에서 y = F(x, w_i) + w_s*x 로 계산
만약 identity의 차원이 다르다면, w_s를 통해 Linear Projection하여 더해준다.
BottleNeck Block
ResNet50 이후의 깊은 모델에서 사용되는 블록이다.
1x1, 3x3, 1x1과 같은 형태의 컨볼루션 레이어를 통해, 데이터의 차원을 줄이고, 연산량은 낮으면서 정보를 효과적으로 전달할 수 있도록 하는 구조이다.
이를 통해 기존 SOTA였던 HighWay나 VGG-16/19보다 더 높은 정확성을 가지면서 오히려 FLOPs는 낮은 결과를 얻어낼 수 있었다.
실험 결과
실험 결과, 위와 같이, 기존 VGG-Like 아키텍쳐로 18레이어와 34레이어를 쌓았을 때는 오히려 plain-34에서 정확도가 낮아지는 경향성을 보였다.
그러나, ResNet의 경우, Layer가 깊어질 수록 효율적으로 학습이 진행되고, 에러율이 줄어들며 점점 더 정확해지는 특성을 확인할 수 있다.
Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertForMultiLabelSequenceClassification 해결법
해당 메시지는 사실 에러가 아니라 워닝으로, 코드 실행에는 문제가 없다.
pretrained 모델을 불러와서 분류, 요약과 같은 down stream task를 실행하고자 할 때 주로 발생하는데,
초기화되지 않은 weight가 있거나, 불러왔는데 사용을 하지 않는 weight가 존재할 때 발생한다.
정상적으로 동작하는데에는 전혀 지장이 없으며, 분류, 요약에 맡게 다시 Fine-Tuning하는 과정이 있기 때문에 초기화되지 않은 weight도 정상적으로 바뀌게 된다. 하지만 이러한 warning이 굉장히 눈에 거슬리고, 멀티프로세싱을 하는 경우 log를 확인하는데 애로사항이 있으므로, 경고 기능을 끌 수 있다.
from transformers import logging
logging.set_verbosity_error()
해당 기능은 Error외에 Warning이나 Information을 제공받지 않도록 하므로, 디버깅 할때는 유용한 정보를 놓치게 될 수도 있지만, 디버깅이 끝나고 정상 동작이 확인된 코드의 경우 위와 같이 Error만 로그를 받겠다고 선언하면 깔끔한 output을 확인할 수 있다. 이 후 워닝이 발생하지 않는다!
python에서 용량이 큰 파일을 다룰 때, 해당 경고 메시지가 발생하게 된다. 생긴게 굉장히 괴랄해서 Error가 뜬 것 처럼 보이지만, 사실 대용량 메모리 할당이 이루어졌을 때 이를 알리는 Warning 정도라고 보면 된다. (물론 실제로 할당 메모리보다 자원이 부족할 경우에는 에러로 이어진다.)