서론
굉장히 오랜만에 블로그 포스팅을 진행하는 것 같다.
2월부터 ICDAR이라고 하는 Document Analysis and Recognition 학회에서 열리는 Competition을 나가게 되었는데,대회가 끊임없이 무한 연장되면서 거의 2달간을 밤을 지새우며 대회에만 집중했다.
Upstage KR이라는 회사 이름을 걸고 대회에 참전하는 대신, 기존에 진행하던 업무들은 잠시 다 내려두고 대회에만 집중할 수 있도록 회사에서 배려해주셨다.
Purdue에서 Kaggle로 Pneumonia Detection을 수박 겉핥기식으로 진행했던 경험이 전부였던 내게,굉장히 큰 도전 같은 업무였다.
현재 내가 회사에서 맡고 있는 역할은, OCR이라고 하는 글자 읽어주는 AI 모듈중글자를 찾아주는 검출기(Detector), 글자 영역을 읽어서 텍스트로 인식하는 인식기(Recognizer)중 인식기를 담당하고 있다.
그러다보니, 자연스럽게 Recognizer의 기술력이 필요한 Task를 찾게 되었고,그렇게 시작된 것이 IHTR이었다.
IHTR?
IHTR은 Indic Handwriting Text Recognition의 약자로, 말 그대로 인도어 손글씨 인식 대회이다.
굉장히 당황스러웠던 점은, 대회의 취지가 "인도어 인식"이 아니라 "인도어군 인식" 이었다는 점이다.
이게 무슨 뜻이냐면,
인도는 인구가 많은 만큼 언어도 굉장히 다양한데, (비공식적으로 3000개의 언어가 있다고 한다.)
인도어군에서 대표적으로 사용되는 10가지 문자 (Bengali, Devanagari, Gujarati, Gurumukhi, Kannada, Malayalam, Odia, Tamil, Telugu, Urdu 를 모두 인식해야하는 Task였다.

2달간의 사투
대회는 정말 끝도 없이 연장되었고, 처음엔 한 달 정도 에너지를 쏟을 각오로 임했으나 결국 두 달을 풀로 써서야 대회가 마무리되었다. 이런 대회를 제대로 참여해본적은 처음이라 어떻게 시작해야할지도 막막했으나, 회사에 존재하는 케글러분들의 도움을 받아 대회 방향성을 잡을 수 있었다.
본 대회에서 좋은 성적을 얻을 수 있었던 이유를 데이터적 관점, 전처리 테크닉, 후처리 테크닉 세가지로 나눠서 기록해보고자 한다.
좋은 모델의 기본은 좋은 데이터!
소제목 그대로, 좋은 모델을 만들려면 양질의 데이터가 필요하다.
IHTR 대회는 특이하게도, 대회에서 제공하는 데이터 외의 추가 데이터도 무제한 허용되는 대회였다.
이러한 점을 적극 활용하기 위해서 첫번째로는, Kaggle과 각종 Paper에 존재하는 온갖 부류의 Indic Text 데이터셋을 수집했다. 거의 열흘을 데이터 수집에만 몰두한 결과 총 18개의 오픈 데이터를 취득할 수 있었다.
그러나 18개의 오픈데이터의 한계점은 명확했다.양이 너무 적었고, Bengali, Devanagari 같이 비교적 많이 쓰이는 문자에 대한 데이터셋은 많이 존재했지만, 본 대회에서 다루는 10가지 언어중 일부는 아예 수집 자체를 못했기 때문이다.
그래서 추가적으로, Text Rendering 툴 Pango를 사용하여 그럴듯한 합성 데이터를 찍어내기로 했다.Upstage 내부적으로도 훌륭한 합성 데이터 엔진이 있었지만, Right-to-Left, 글자 4개가 합쳐져서 1개의 글자가 되는 복잡한 인도어의 특성상 기존 영문/국문 합성 데이터 엔진과는 호환이 되지 않는 문제가 있어서 간단하게 Pango라는 CLI 기반 렌더링 라이브러리를 적용하기로 했다.
아래 데이터는 실제로 직접 생성한 합성데이터의 예시이다.최대한 렌더링에 사용되는 폰트는 손글씨와 비슷해보이는 폰트를 선택하였고, 배경은 종이 질감 이미지를 구해서 사용하였다.



위와 같은 합성데이터를 언어별로 100,000장씩 생성하여 학습에 이용하였고, 성능이 크게 개선되었다.
전처리 테크닉
위와 같이 다양한 데이터를 수집하여 정확도를 끌어올리는 것은 성공하였으나, 그럼에도 불구하고 만족스러운 성능이 나오지는 않았다. 특이한점은 Train Set에서의 정확도는 거의 100%에 loss도 정상적으로 훅훅 줄어드는데, Validation Set에서의 성능이 70% 정도 수준에서 오르지 않고 제자리 걸음이었던 점이다.
데이터를 직접 까보니, 아래 그림과 같이 Train Set과 Validation Set의 이미지 형태가 너무 달라서 발생하는 문제라는 것을 깨닫고 아래의 2가지 방법을 시도했다.

1. 기존 Upstage의 Recognizer가 잘 동작한 이유는, Detector가 이미지 내의 Word 영역을 Tight하게 Crop해주었기 때문이다. 이걸 Rule Base로 잘라보면 어떨까?
cv2의 otsu threshold를 이용하여, 아래와 같이 이미지의 Word 영역만 잘라줘서 Train을 진행한 후 정확도가 크게 상승했다.


2. Train Set의 해상도는 전반적으로 고화질이고, 배경색이 깔끔한 흰색 종이 바탕인 반면, Validation Set은 핸드폰 카메라로 마구 찍은 것 처럼 화질도 좋지 않고, 노이즈도 심한 상태였다. 이를 Neural Style Transfer로 맞춰주면 어떨까?
Neural Style Transfer는 Image를 통계적으로 유사하게끔 Augmentation 해주는 모델로, 사람이 직접 Augmentation 파이프라인을 개발할 필요 없이 샘플 이미지만 입력으로 넣어주면, 해당 샘플 이미지와 비슷한 형태로 이미지를 만들어주는 장점이 있다. 이를 활용하여 아래와 같은 결과를 얻을 수 있었다.

위 두가지 방법론을 적용하여 드디어 정확도 90%대를 달성할 수 있었고, 대회 리더보드 1위를 달성했다.
후처리 테크닉
위 결과에서 정확도 90%대로 대회 리더보드상으로 압도적인 1위를 하며 방심할 때 즈음,
ICDAR 2021에서 클로바팀을 꺾고 우승을 했던 PERO OCR이라는 강팀이 나타났고,
우리의 1위를 빼앗아갔다.
대회 마감 1주일 전이었다.
하지만 우리에게도 아직 남겨둔 카드가 있었다.
Kaggle 같은 대회의 꽃, Ensemble이다.
나와 본 대회에 같이 참여했던 동료분은 OCR Recognizer만 회사에서 1년째 담당하고 있으신 상태로, 수많은 대기업 PoC를 진행해오면서 점수를 끌어올리는 방법론에 일가견이 있는 상태였다.
인식 Charset 제한, Multilingual로 Pretrain한 후, Single Language 특화 모델로 Fine-tuning등등 PoC로 다져진 모델 찍어내기 능력과 회사의 빵빵한 A100 장비와 AI 플랫폼 클러스터를 활용하여 언어별로 수백개의 Single Model을 만들었고,
각각의 모델의 Output을 투표하여 합치는 Weighted Hard Voting 방식으로 정확도 95.775%를 달성, 대회 마지막날 기적적인 역전승에 성공하게 되었다!
결과 및 후기
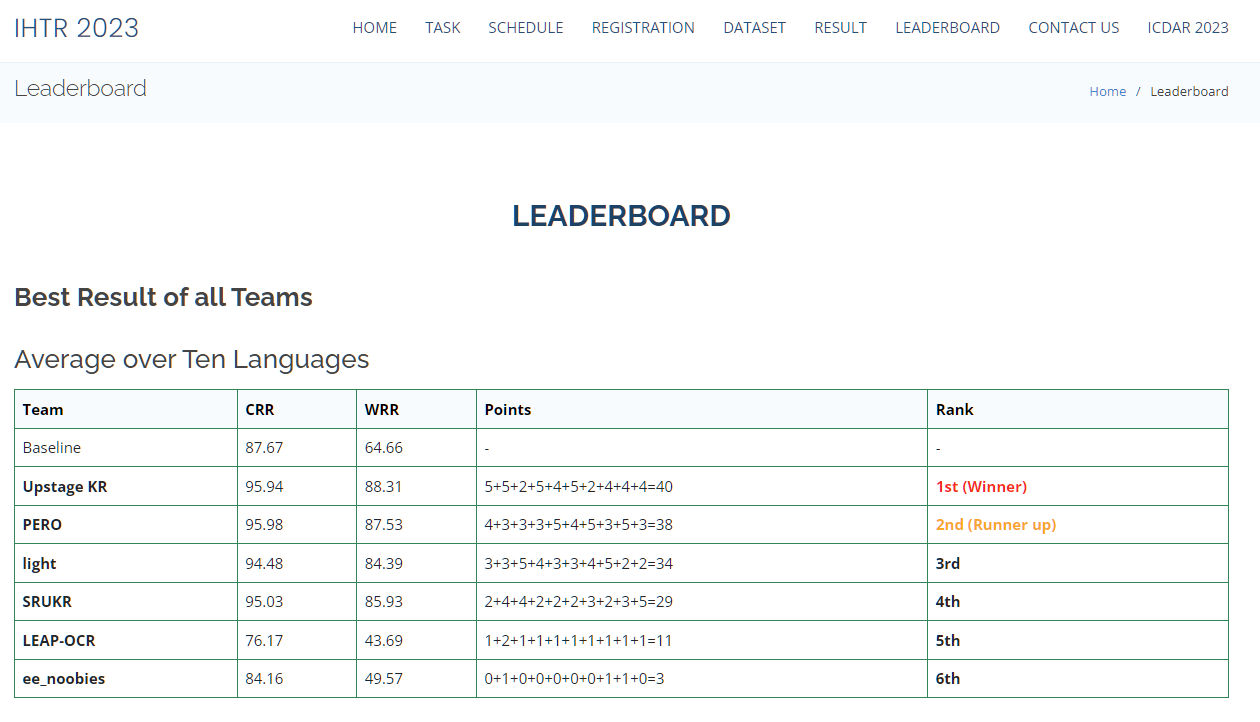
두 달간 잠도 못자고 열심히 달린 결과 당당히 1위를 달성했고,
우리 팀 외에도 ICDAR Competition에 참가하신 다른 팀분들도 무려 3팀이나 추가로 1위를 달성하시면서 아래와 같은 뉴스 기사가 쏟아지게 되었다.
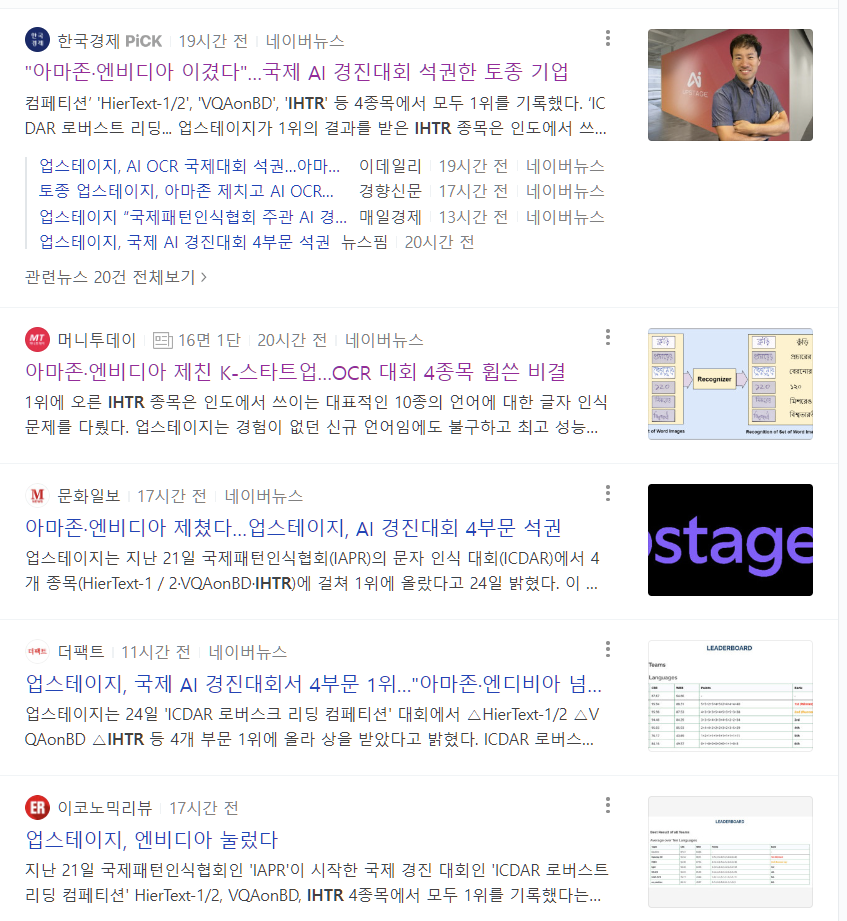
주니어 AI 개발자로써, Kaggle이나 학회 Competition등에 한번쯤은 참가해서 좋은 성적을 받아보고 싶다는 생각이 있었는데, 모처럼 너무 좋은 기회를 만나서 멋진 경험을 할 수 있었다. 두 달간 사실 회사 매출엔 딱히 도움이 안되는 ICDAR Competition에 100% 집중할 수 있게끔 배려해주신 팀원분들과 리더분께 감사를 표하고 싶다.
근데 리더보드가 매일 뒤바뀌는 막판엔 정말 너무 힘들었어서......
당분간은 이런 대회는 피하고 싶다... ㅎㅎㅎㅎ
충분한 회복기를 거친 후에, Kaggle에 도전해보는 걸로!
Reference: https://ilocr.iiit.ac.in/ihtr/
'About Me > 일상' 카테고리의 다른 글
| 뒤늦게 써보는 2021년 회고(Feat. AI 전문연구요원 합격) (10) | 2022.01.23 |
|---|---|
| [논문영문교정] 해외 저널 논문 영어 교정 후기 (1) | 2021.10.20 |
| [잔여백신 / 화이자] 20대 화이자 잔여백신 후기, 예약 팁 (0) | 2021.07.28 |

Hyunsoo Luke HA
석사를 마치고 현재는 Upstage에서 전문연구요원으로 활동중인 AI 개발자의 삽질 일지입니다! 이해한 내용을 정리하는 용도로 만들었으니, 틀린 내용이 있으면 자유롭게 의견 남겨주세요!