


[논문 리뷰] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Machine Learning/Deep Learning 논문 2021. 12. 12. 06:39반응형

Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
얼마전, 기업 코딩 테스트를 진행하면서, 딥러닝 과제를 푸는 전형이 있었는데, Swin Transformer가 그 역할을 확실히 해주었었다. Microsoft에서 발표하고, Object Detection, Segmentation에서 SOTA를 달성했었고, 아직까지도 준수한 성능을 가지는 Backbone으로 활용되고 있는 Swin Transformer에 대해 간단히 알아보자.
연구의 배경
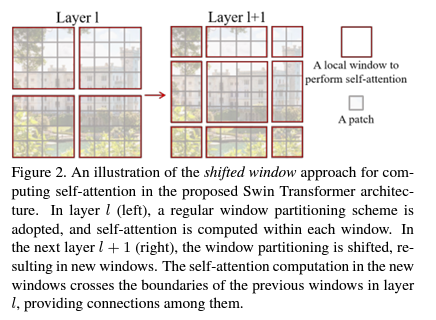
- 대부분의 Vision Task는 CNN이 우세한 성능을 가지고 있으나, 최근 ViT와 같은 논문이 발표됨에 따라, Transformer구조를 Vision 분야에 가져오려고 하는 시도가 많다.
- 본 논문의 저자들은 Transformer 기반의 Backbone을 제공하되, CNN이 Vision Task에서 수행하는 Role을 일부 차용하여 Vision Task에서 효과적으로 Backbone으로 사용될 수 있는 Swin Transformer를 제안한다.
- 저자들은 Transformer가 Vision Task에서는 효과가 적고, NLP 분야에서는 효과적인 이유에 대해 2가지 차이점을 바탕으로 설명한다.
- 첫째는, Vision Task에서는 시각적 객체들이 서로 다른 Scale을 가진다는 점으로 ViT 모델들이 항상 Fixed Scale로 접근하기 때문에 Object Detection이나, Segmentation과 같이 Scale에 민감한 Task를 잘 처리하지 못한다는 점
- 둘째는, Image Segmentation과 같은 경우 Pixel 하나 하나에 대해서 굉장히 민감한 Task인데 ViT 방식의 경우 고해상도 Image에 대해서 Quadratic 하게 증가하는 연산량으로 인해서 고해상도 이미지를 그대로 사용할 수 없거나, 학습에 굉장히 오랜 시간과 비용이 든다는 점이다.
- Swin Transformer는 Shifted Window 개념을 통해 다양한 Scale을 살필 수 있도록 계층 구조를 만들고, 이미지 Size에 대해서 Linear하게 연산량이 증가하는 방식의 Backbone을 제안한다.
- Small-Size Patch부터 계산을 진행하며, 점점 병합을 통해 큰 Patch Size를 확인하는 계층적 방식을 가지고 있으며 이를 통해 마치 FPN이나 U-Net과 같이 다양한 Object Scale을 고려할 수 있게 된다.
- 또한 Shifted Window 내부에 존재하는 patch들 간에만 Self Attention을 계산하는 방식을 통해 계산량을 획기적으로 감소시켰다.
Architecture
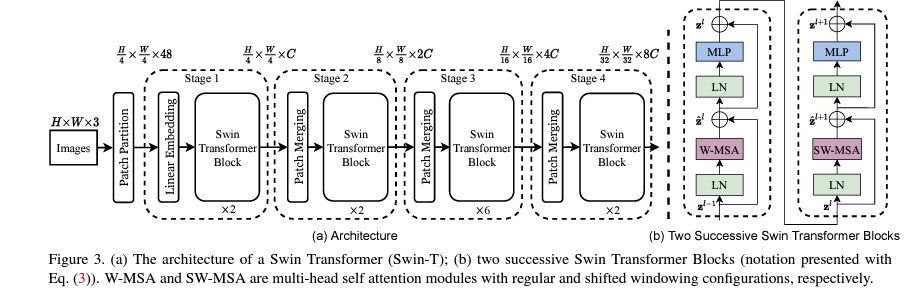
- Patch Partition, Linear Embedding, Swin Transformer Block, Patch Merging으로 구성되어 있다.
- Swin Transformer Block은 2개의 Encoder로 구성되어 있으며, Window Multi-Head Self Attention, Shifted Window Multi-Head Self Attention으로 구성된다.
- 이러한 W-MSA, SW-MSA는 Window 내부에 존재하는 Patch끼리만 Self Attention 연산을 수행한다. 이는 Vision Task에서는 주변 Pixel끼리의 연관성이 높기 때문이다. 기존 Self Attention의 경우 NLP에서는 문장 맨 앞에 있던 Token과 맨 뒤에 있던 Token끼리의 연관성이 높은 경우도 더러 존재하고, 효과적으로 문맥을 이해하기 위해 모든 Attention을 계산하다보니 Image Size가 커지면 Patch가 기하급수적으로 많아지며 연산량이 Quadratic하게 증가하는 반면, Swin Transformer에서는 Vision의 특성을 고려하여 인접 영역만 체크하도록 한 것이다. 이는 CNN이 Filter를 통해 연산하는 것과 비슷한 방식의 접근이라고 보인다.
- 하지만 W-MSA만을 이용할 경우, Window간의 연관관계를 파악할 수 없고 이로 인해 이미지 전체를 인식하는데 어려움이 발생한다. 저자들은 Window간의 Connection을 학습하면서, 연산량의 효율성은 그대로 유지하기 위해서 Shifted Window MSA를 제안한다.
SW-MSA
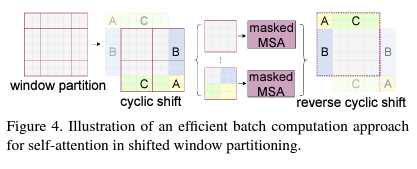
- Window Partition을 나누고, 각 윈도우 간의 상관관계를 찾아내는 것이 Classification, Object Detection, Semantic Segmentation등에 큰 효과를 지니기 때문에 본 논문의 저자들은 SW-MSA를 제안하였다.
- Window를 Shift하고 Padding을 추가하는 방식도 가능하고 구현상 더 편리하지만, 그렇게 할 경우 연산량이 크게 증가하는 부작용이 존재한다.
- 따라서 본 논문에서는 위 그림과 같이 Cyclic Shift를 진행한 뒤, 실제로는 이웃하지 않은 Patch인 A,B,C에 대해서는 Mask를 통해 Attention을 계산하지 않도록 구현한다.
- 그 후, 원상태로 복원시킴으로써, 효율적으로 Window간의 상관관계를 학습할 수 있도록 한다.
Relative Position Bias

- Swin Transformer는 ViT와 달리 Positional Embedding을 입력부분에서 추가하지 않고 Relative Position Bias를 활용한다.
- 또한, ViT에 사용된 Absolute Position Embedding 보다는, 각 Patch간에 위치를 의미하는 Relative Position Bias가 효과적이었다는 것을 실험을 통해 확인하였다.
Result

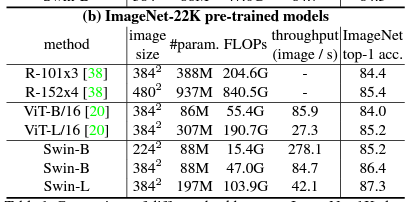
- ImageNet Classification 에서 SOTA 달성
- 뿐만 아니라 ImageNet을 통해 학습된 모델을 Backbone으로 사용하였을 때, Object Detection, Segmentation 쪽에서도 SOTA를 달성하였다.
- 또한, Vision Transformer 류의 특성답게 학습 데이터가 많아질 수록 Accuracy와 mAP가 증가하는 추세를 보였다.
- Classification은 금방 SOTA에서 밀려났지만, Multi-Scale이 중요한 Object Detection, Segmentation 쪽에서는 아직까지도 SOTA를 유지하고 있다.
Conclusion
- 본 논문은 Vision Task와 NLP의 차이점을 명확히 구분하고, 가장 Vision Task에 잘 맞는 방식으로 Transformer를 적용한 Swin Transformer를 제안하였으며, 다양한 Vision Task에서 EfficientNet B7을 능가하거나 맞먹는 수준의 높은 성능을 보여주었다.
- 또한 Linear한 계산 복잡도를 가지므로, 고 해상도 이미지를 효과적으로 학습시킬 수 있는 방식을 제안하였다.
개인적으로 의문이 든 점
- 과거 진행했던 ViT와 CNN을 결합한 DeepFake Detection 연구에서는 Vision Transformer가 낮은 Inductive Bias를 바탕으로 높은 Generalization 성능을 가지고 있어서 Ensemble을 통해 측면 얼굴, 저해상도, 그림자 진 얼굴등에 대해 효과적으로 분류하는 것을 확인할 수 있었는데, 과연 CNN과 같이 Inductive Bias가 부여된 Swin Transformer와 Ensemble 해도 동일한 효과가 날까?
- 결국 이런 방식으로 간다면 CNN을 잘 개선하는 것과 유의미한 차이가 있는가? 오히려 Transformer의 장점이 옅어질 수도 있을 것 같다.
반응형
'Machine Learning > Deep Learning 논문' 카테고리의 다른 글
| [논문 리뷰] CMT: Convolutional Neural Networks Meet Vision Transformers (0) | 2021.12.13 |
|---|---|
| [논문 리뷰] YOLOX: Exceeding YOLO Series in 2021 (1) | 2021.12.13 |
| [논문 리뷰] Attention Is All You Need(Transformer) (0) | 2021.12.12 |
| [논문 구현] Pytorch 기반 ResNeXt 구현 및 CIFAR10 실험 (0) | 2021.10.18 |
| [논문 리뷰] ResNeXt : Aggregated Residual Transformations for Deep Neural Networks (0) | 2021.10.18 |

Hyunsoo Luke HA
석사를 마치고 현재는 Upstage에서 전문연구요원으로 활동중인 AI 개발자의 삽질 일지입니다! 이해한 내용을 정리하는 용도로 만들었으니, 틀린 내용이 있으면 자유롭게 의견 남겨주세요!